 |
CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning
Liyiming Ke*, Yunchu Zhang*, Abhay Deshpande, Siddhartha Srinivasa, Abhishek Gupta
arXiv 2023
We present a new technique to enhance the robustness of imitation learning methods by generating corrective data to account for compounding errors and disturbances. While existing methods rely on interactive expert labeling, additional offline datasets, or domain-specific invariances, our approach requires minimal additional assumptions beyond access to expert data. The key insight is to leverage local continuity in the environment dynamics to generate corrective labels. Our method first constructs a dynamics model from the expert demonstration, encouraging local Lipschitz continuity in the learned model. In locally continuous regions, this model allows us to generate corrective labels within the neighborhood of the demonstrations but beyond the actual set of states and actions in the dataset. Training on this augmented data enhances the agent's ability to recover from perturbations and deal with compounding errors. We demonstrate the effectiveness of our generated labels through experiments in a variety of robotics domains in simulation that have distinct forms of continuity and discontinuity, including classic control problems, drone flying, navigation with high-dimensional sensor observations, legged locomotion, and tabletop manipulation.
@inproceedings{ke2023ccil,
title={CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning},
author={Ke, Liyiming and Zhang, Yunchu and Deshpande, Abhay and Srinivasa, Siddhartha and Gupta, Abhishek},
booktitle={none},
year={2023}}
|
 |
Cherry Picking with Reinforcement Learning
Yunchu Zhang*, Liyiming Ke*, Abhay Deshpande, Abhishek Gupta, Siddhartha Srinivasa
RSS 2023
We developed a system for fine manipulation of small objects  without rigid surface support (floating without rigid surface support (floating  , windy , windy  , human disturbance) using chopsticks (simple tool for fine manipulation). , human disturbance) using chopsticks (simple tool for fine manipulation).
 The task requires <1mm precision (even in static scene), and we add unmodeled dynamic disturbance The task requires <1mm precision (even in static scene), and we add unmodeled dynamic disturbance
 Only 30 minutes of real world interactions Only 30 minutes of real world interactions
 Plug in any off-the-shelf pose estimation module for deployment. Plug in any off-the-shelf pose estimation module for deployment.
 Too lazy for parameter tuning = off-the-shelf RL algo + default params Too lazy for parameter tuning = off-the-shelf RL algo + default params
 is to understand the impact of each the design choice is to understand the impact of each the design choice
@inproceedings{zhang2023cherry,
title={Cherry Picking with Reinforcement Learning},
author={Zhang, Yunchu and Ke, Liyiming and Deshpande, Abhay and Gupta, Abhishek and Srinivasa, Siddhartha},
booktitle={Proceedings of Robotics Science and Systems (RSS)},
year={2023}}
|
 |
Real World Offline Reinforcement Learning with Realistic Data Sources
Gaoyue Zhou*, Liyiming Ke*, Siddhartha Srinivasa, Abhinav Gupta, Aravind Rajeswaran, Vikash Kumar
ICRA 2023
In Real World
When to pick OfflineRL (ORL) over BC?
What settings to use for ORL?
Does ORL generalize to tasks with low data support?
Can ORL handle non-stationary settings?
Can ORL leverage multi-task data to improve?
@inproceedings{zhou2023orl,
title={Real World Offline Reinforcement Learning with Realistic Data Sources},
author={Zhou, Gaoyue and Ke, Liyiming and Srinivasa, Siddhartha and Gupta, Abhinav and Rajeswaran, Aravind and Kumar, Vikash},
booktitle={arXiv preprint arXiv 2210.06479},
year={2023}}
|
 |
Grasping with Chopsticks: Combating Covariate Shift in Model-free Imitation Learning for Fine Manipulation
Liyiming Ke, Jingqiang Wang, Tapomayukh Bhattacharjee, Byron Boots, Siddhartha S. Srinivasa
ICRA 2021
Can you use chopsticks to grasp tiny balls  ? ?
The radius of the ball is 7mm or 10mm. So, if you miss the grasping point by 0.5mm, the task would fail. We taught a robot to use chopsticks to autonomously grasp these tiny objects at 80% success rate, comparable to human expert performance of 82.6%. We do so by imitation learning and our baseline, naive behavior cloning, has only 37.3% success rate. We proposed three novels approaches to combat covariate shift.
@inproceedings{ke2021grasping,
title={Grasping with Chopsticks: Combating Covariate Shift in Model-free Imitation Learning for Fine Manipulation},
author={Ke, Liyiming and Wang, Jingqiang and Bhattacharjee, Tapomayukh and Boots, Byron and Srinivasa, Siddhartha},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2021}}
|
 |
Telemanipulation with Chopsticks: Analyzing Human Factors in User Demonstrations
Liyiming Ke, Ajinkya Kamat, Jingqiang Wang, Tapomayukh Bhattacharjee, Christoforos Mavrogiannis, Siddhartha S. Srinivasa
IROS 2020
Billions of people use chopsticks, a simple yet versatile tool, for fine manipulation of everyday objects. We built a chopsticks-equipped robot and a teleoperation interface to study human manipulation strategies. 25 human subjects used our system to pick up different objects, including a slippery glass ball. Although participants rated teleoperation as the least comfortable and most difficult-to-use method, teleoperation enabled users to achieve the highest success rates on three out of five objects considered.
@inproceedings{ke2020telemanipulation,
title={Telemanipulation with Chopsticks: Analyzing Human Factors in User Demonstrations},
author={Ke, Liyiming and Kamat, Ajinkya and Wang, Jingqiang and Bhattacharjee, Tapomayukh and Mavrogiannis, Christoforos and Srinivasa, Siddhartha S},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2020}}
|
 |
Imitation Learning as f-Divergence Minimization
Liyiming Ke, Sanjiban Choudhury, Matt Barnes, Wen Sun, Gilwoo Lee, Siddhartha Srinivasa
WAFR 2020
We propose a general framework for imitation learning (IL), formulating IL as estimating and minimizing f-Divergence. By plugging in different divergences, we are able to recover existing SOTA IL algorithms such as Behavior Cloning, GAIL and Dagger. Our framework shows that these algorithms are all minimizing a lower bound of the trajectory divergence between learner and expert.
@inproceedings{ke2020imitation,
title={Imitation Learning as f-Divergence Minimization},
author={Ke, Liyiming and Choudhury, Sanjiban and Barnes, Matt and Sun, Wen and Lee, Gilwoo and Srinivasa, Siddhartha},
booktitle={International Workshop on the Algorithmic Foundations of Robotics},
year={2020}}
|
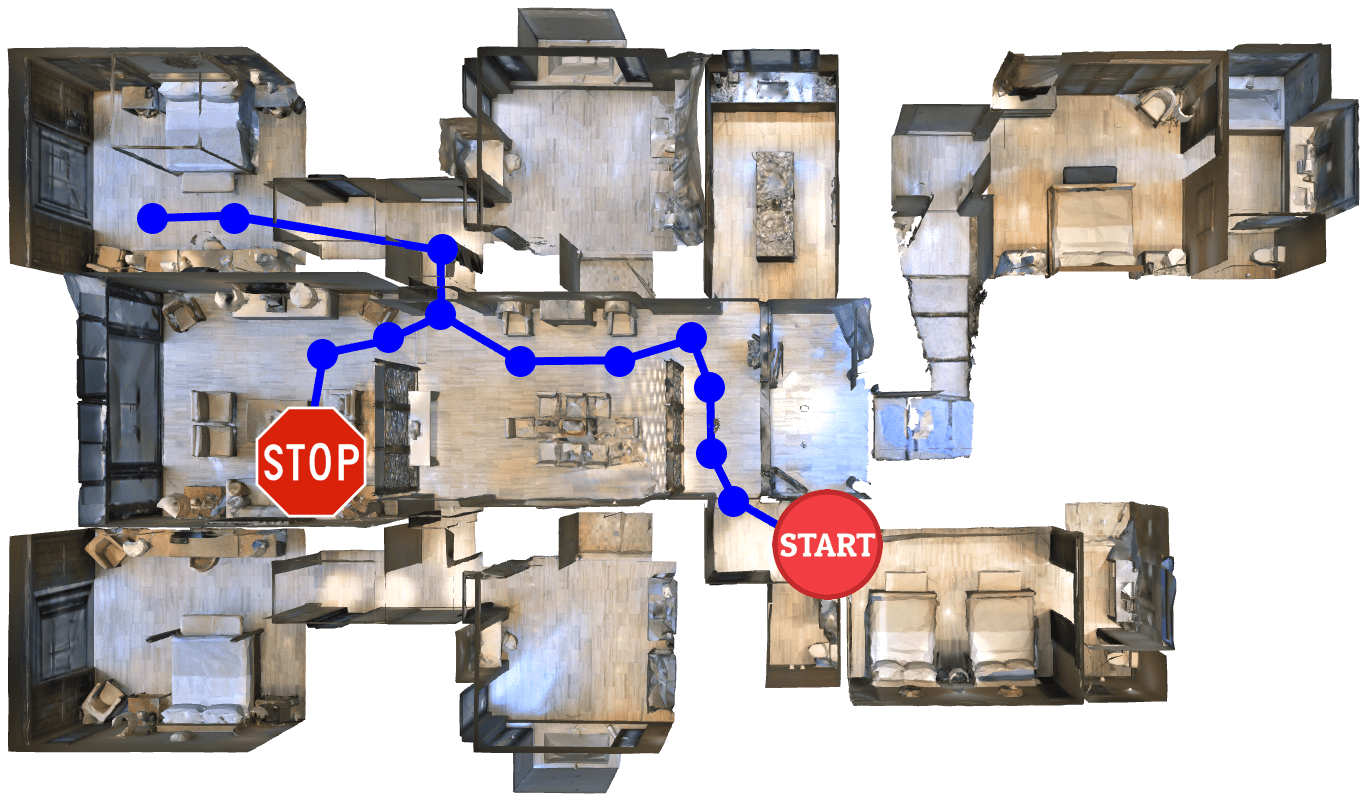 |
Tactical Rewind: Self-Correction via Backtracking in Vision-and-Language Navigation
Liyiming Ke, Xiujun Li, Yonatan Bisk, Ari Holtzman, Zhe Gan, Jingjing Liu, Jianfeng Gao, Yejin Choi, Siddhartha Srinivasa.
CVPR 2019 Oral(5.6%)
We propose to combine neural network and search, teaching an agent to follow natural language instructions to navigate in a photorealistic house. We use local signals to act greedily and global signals to backtrack when exploring the environment. Our framework is simple and can be applied to any seq2seq agent with no training required. We achieved new SoTA at the time of submission.
@inproceedings{ke2019tactile,
title={Tactical Rewind: Self-Correction via Backtracking in Vision-and-Language Navigation},
author={Ke, Liyiming and Li, Xiujun and Bisk, Yonatan and Holtzman, Ari and Gan, Zhe and Liu, Jingjing and Gao, Jianfeng and Choi, Yejin and Srinivasa, Siddhartha},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019 Oral(5.6%)}}
|
 |
Behavioral Experiments in Email Filter Evasion
Liyiming Ke, Bo Li , Yevgeniy Vorobeychik
AAAI 2016
We investigate how human subjects manipulate a spam template to evade a classification-based filter. We find that adding a small amount of noise to a filter significantly reduces the ability of subjects to evade it. We develop a synthetic model of human evasion behavior.
@inproceedings{ke2016behavioral,
title={Behavioral Experiments in Email Filter Evasion},
author={Ke, Liyiming and Li, Bo and Vorobeychik, Yevgeniy},
booktitle={Thirtieth AAAI Conference on Artificial Intelligence (AAAI)},
year={2016}}
|